Part 0: Testing Images
We procured images just to test how things work.



All these images were produced using a seed of 356. We experimented with different inference steps.


Part 1.1: Implementing the Forward Process
A key part of diffusion is the forward process, which takes a clean image and adds noise to it. In this part, we implemented this process using the following equations:
q(xt | x0) = N(xt ; √(ᾱt) x0, (1 - ᾱt) I)
xt = √(ᾱt) x0 + √(1 - ᾱt) ε, where ε ~ N(0, 1)
Given a clean image x0, we get a noisy image xt at timestep t by sampling from a Gaussian with mean √(ᾱt) x0 and variance (1 - ᾱt). Note that the forward process not only adds noise but also scales the image.
We used the alphas_cumprod variable, which contains the ᾱt for all t ∈ [0, 999]. Since t = 0 corresponds to a clean image and larger t corresponds to more noise, ᾱt is close to 1 for small t and close to 0 for large t.
We ran the forward process on the test image with t ∈ [250, 500, 750]. Below are the results, showing progressively noisier images.

Part 1.2: Naively Denoising with Gaussian Blur
We attempted to naively smooth out the noise by applying a Gaussian blur to the noisy images.

Part 1.3: Denoising with a Pretrained Diffusion Model
We used a pretrained diffusion model to denoise the images. The UNet model stage_1.unet has been trained on a large dataset of (x0, xt) pairs of images. It can recover Gaussian noise from the image, allowing us to estimate the original image by effectively reversing the noise addition process.

Part 1.4: Iterative Denoising
While the UNet model performs well, it struggles with images that have higher noise levels. To improve the results, we implemented an iterative denoising process using the following equation:
xt' = [√(ᾱt') βt / (1 - ᾱt)] x0 + [√(αt)(1 - ᾱt') / (1 - ᾱt)] xt + vσ
Where:
- xt is the image at timestep t
- xt' is the image at timestep t' (less noisy, t' < t)
- αt = ᾱt / ᾱt'
- βt = 1 - αt
- x0 is our current estimate of the clean image
This process allows us to skip steps and denoise more efficiently.


Part 1.5 and 1.6: Generating Images from Scratch and Classifier-Free Guidance
Using the iterative_denoise function, we generated images from scratch by starting with random noise and setting i_start = 0. This allows the model to create images based on the text prompt "a high quality photo."
We implemented Classifier-Free Guidance (CFG) to enhance image quality. In CFG, we compute both a noise estimate conditioned on a text prompt (εc) and an unconditional noise estimate (εu). We then compute:
ε = εu + γ (εc - εu)
Where γ controls the strength of CFG. Setting γ > 1 leads to higher quality images by amplifying the effect of the conditioning prompt.


Part 1.7: Image Editing with Diffusion Models
We explored how adding noise to a real image and then denoising it can effectively edit the image. The more noise we add, the more significant the edits. This works because the denoising process forces the noisy image back onto the manifold of natural images, allowing the model to "hallucinate" new content.





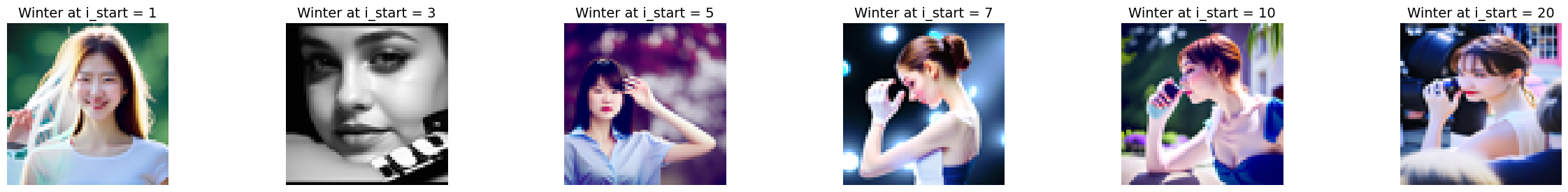
Part 1.7.1: Applying Edits to Web and Hand-Drawn Images
We applied these editing techniques to images downloaded from the web and hand-drawn images.
Web Image:


Hand-Drawn Images:




Part 1.7.2: Inpainting with Diffusion Models
We implemented inpainting using the RePaint approach. Given an image xorig and a binary mask m, we created a new image that preserves the original content where m = 0 and generates new content where m = 1. At each denoising step, we updated xt as:
xt ← m xt + (1 - m) forward(xorig, t)
This ensures that regions outside the mask remain unchanged while the model inpaints the masked areas.


Part 1.7.3: Text-Conditioned Image-to-Image Translation
We performed image-to-image translation guided by text prompts. By changing the prompt from "a high quality photo" to specific descriptions, we manipulated the image content in a controlled manner.



Part 1.8: Creating Visual Anagrams
We implemented Visual Anagrams to create optical illusions with diffusion models. For example, we created an image that looks like "an oil painting of an old man," but when flipped upside down reveals "an oil painting of people around a campfire."
We achieved this by denoising an image xt with two different prompts, flipping one of the noise estimates, and averaging them:
ε1 = UNet(xt, t, p1)
ε2 = flip(UNet(flip(xt), t, p2))
ε = (ε1 + ε2) / 2



Part 1.9: Creating Hybrid Images with Factorized Diffusion
We implemented Factorized Diffusion to create hybrid images, combining elements from two different prompts. We merged low frequencies from one noise estimate with high frequencies from another:
ε1 = UNet(xt, t, p1)
ε2 = UNet(xt, t, p2)
ε = lowpass(ε1) + highpass(ε2)



Project 5B
Part 1: Training a Single-Step Denoising U-Net
In this part of the project, we trained a U-Net to denoise a noisy MNIST digit. To create the training dataset, we added noise to the MNIST images. Here are some examples of varying noise levels:

Here is our training loss over epochs:
Here are sample results after the first epoch:

And here are sample results after the fifth epoch:

We also ran the model on varying sigma values to observe its performance:

Part 2: Training a Diffusion Model
Adding Time-Conditioning
We modified our U-Net to predict the noise of an image instead of performing the denoising itself. This approach allows for iterative denoising, which works better than one-step denoising. By adding conditioning on the timestep of the diffusion process, the model understands which step we are at in the iterative denoising process.
To train the model, we took a batch of random images, added noise to each image with a random timestep value from 0 to 299 using the first equation from Part A (0 being no noise and 299 being pure noise), ran the model on the noisy images to get the predicted noise, and then calculated the loss between the predicted noise and the actual noise added.
To sample from the model, we ran the iterative denoising algorithm from Part A. Starting from an image of pure noise, we iteratively moved towards the clean image. Since the model was trained equally on all noise levels, it should properly denoise the image after sufficient training. Here is our training loss graph:
Here are the sample results after the fifth epoch:

And here are the sample results after the twentieth epoch:

Adding Class-Conditioning
In the previous section, the model struggled to generate distinct digits because it lacked the ability to distinguish between different numbers, often producing amalgamations. To address this, we added class-conditioning to our U-Net, providing the specific digit label to guide the generation process.
The training algorithm remained largely the same, but we included the MNIST labels as a "class" vector input to the U-Net. When sampling, we passed in the class vector corresponding to the desired digit. Here are some results from training the class-conditioned U-Net.